There are times when I am confounded with the great questions of life:
Why does the whiteboard eraser at work erase cleanly while the eraser at home doesn’t erase at all?
Peaks
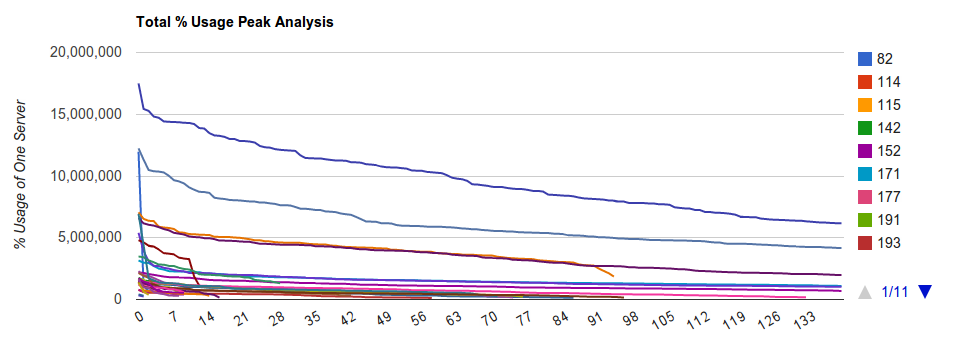
This chart shows the amount of money won monthly by various CIA operatives playing poker. This data shows the peaks for each operative.
Peak analysis finds and orders the peaks of a data set. This data can then be easily graphed, as was done above. One thing to point out here is that this particular data shows only peaks - it doesn’t show dips. The below graph shows which values are included in a ‘normal’ peak analysis:
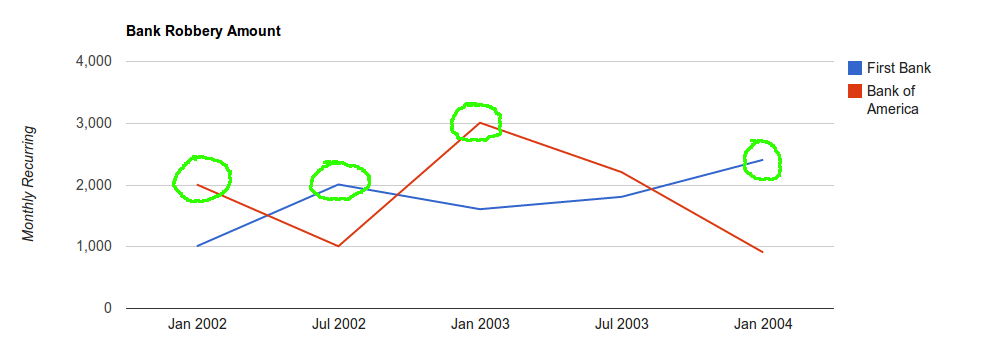
Even if the July 2003 First Bank data point were higher than the July 2002 data point, it wouldn’t be included in a peak analysis (unless it was higher than January 2004). This feature can be disabled, although at that point MySQL can do the work for you. Here’s a code sample:
$chartmeta = array(); $chartdata = get_peaks_mysql($pokerdata, 'agent_id', 'revenue', 140); chart_draw_linechart($chartmeta, $chartdata);
‘pokerdata’ came from a mysql_query_all call, or similar. The last parameter to get_peaks_mysql is optional, and caps the number of peaks returned. The second parameter defines which field, from the MySQL data, segregates the data into series’s. The third value, ‘revenue’, defines the Y-axis value, which is what we’re using in the peak analysis.
There is a fifth, optional parameter that is not shown. This parameter determines whether or not to include lows in the calculation. If dips are included, then all data points will be included - Not just the peaks that were shown above in green circles. True indicates that lows are included.
Peaks - Again
There’s a second API for using peak analysis. get_peaks is not as flexible as the last one, but it is simpler to use. It takes a single argument, data, and outputs a single list of peaks, unlike get_peaks_mysql which outputs an entire graph. If you really want, it will accept a second argument, which defines the data key if the data is an associative array (i.e. mysql data). However, it will still output a single array, and will not segregate based on series, color, race, age, gender, etc.:
$data = array(7, 8, 4, 1, 5, 6, 2, 6, 3, 5, 1, 8); pp(get_peaks($data)); Outputs: (8,6,6,5)
Notice that it does not capture the first or last data point. Also notice that it captures only one of the fives - This is because only one of them, the second one, is higher than it’s neighbors.
What is this used for?
Looking at the first graph, we can see that the highest peak for agent #82, peak zero, is at $17.5 million. However, the next lowest peak, peak one, is almost $15 million lower. Overall, notice that agent #82’s line is generally higher than the others. This means that agent 82 tends to win a lot, but they have won very large sums a few times.
Compare this with agent #171: They won $10 million once. Then they won money on the order of dollars. Clearly not a winner, but when they do win…
Be warned: Carefully consider whether or not to include lows, because if not we don’t know that agent #82 hit zero every other month. In this case, including lows is a good idea. Treating the data as it really is, then including lows is a bad idea, for the sole reason that we’re optimizing for highs.
