1,157 comments in three short weeks. I’m deeply saddened by Google’s recaptcha.
But, today starts the last week of UT! Also, it’s the first day of December/Advent stories.
Now that it’s the last week of UT, I’m going to talk about using less as a PDF parser.
Remember the UT Class picker? So the data that uses is from the registrar’s PDF download of the class schedules. ALL of the class schedules.
Obviously, this is a lot to parse for one little guy. Unfortunately, the PDF format, while human-readable, is written in such a way that it’s nigh impossible for machines to read. Python has a few libraries for reading PDFs, which work fine, except that PDF has a notion of “text boxes” which are represented.
Allow me to briefly interject with the page structure. In general the pages contain two columns, each containing a list of classes. Each class contains zero or more “uniques” which designate the specific dates and times that you can take the class at.
Simple enough, except for text boxes. Which you might think, okay, one for each class? No. One for each unique? No. One for each type of text? No.
To be honest, I don’t know exactly how they decided, only that some text boxes were a half-sentence of a class description, and some contained text for multiple classes. It wasn’t feasible without rendering the document to make sense of the document.
Until I discovered that less provides a PDF renderer. A quick little beauty:
less schedules.pdf > schedules.txt
Produces a file that looks roughly like:
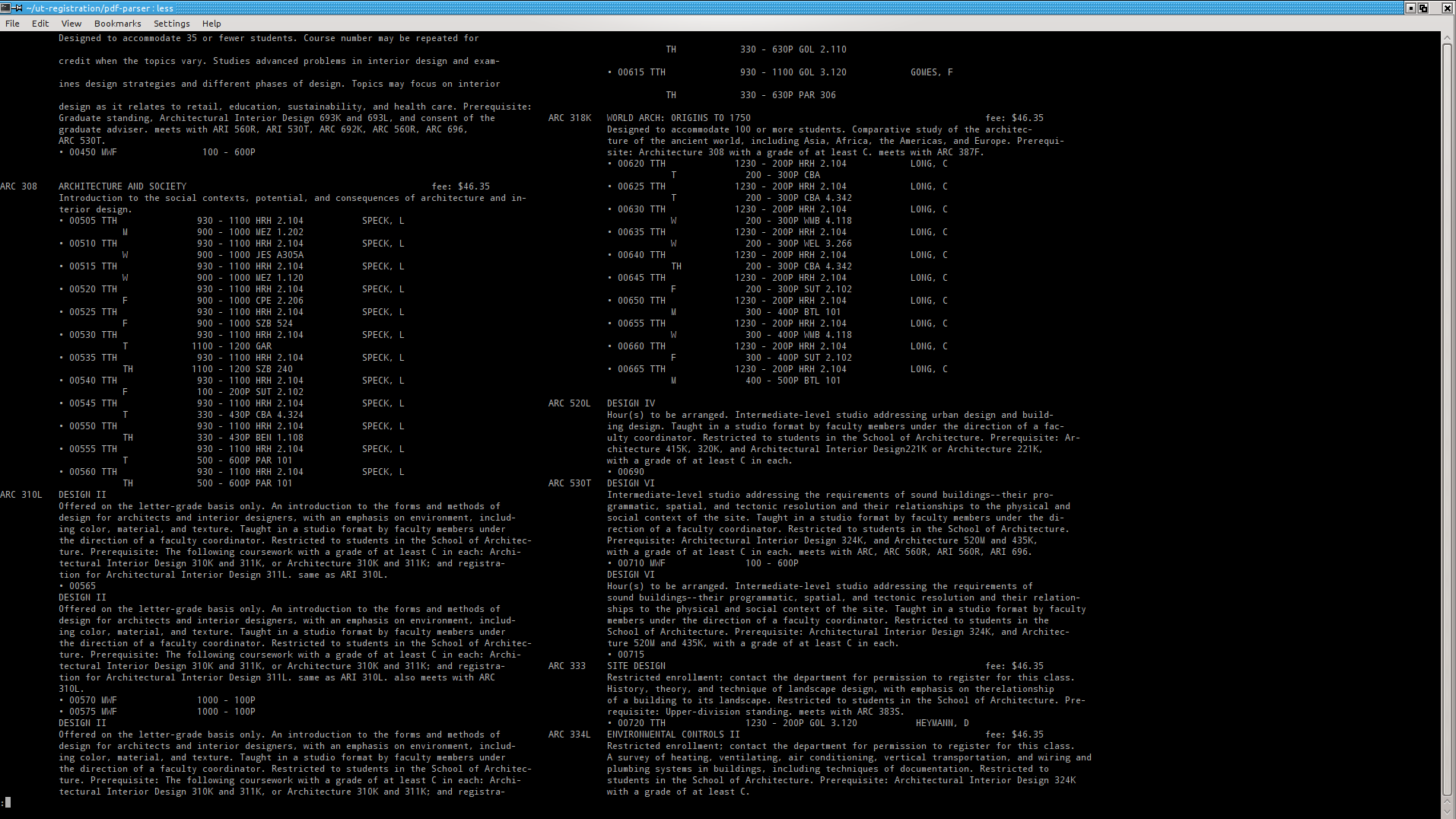
Which clearly has a two-column layout which is trivial for a series of simple pattern-matching type of scripts to detect and parse out.
Mission accomplished.
Less to the rescue!
(Also, Mama Fu’s was my food of November.)
