So over Thanksgiving weekend my family and I went go-kart racing at K1 Speed, a multinational chain indoor electric go-kart racing establishment.
I too didn’t think that indoor go-kart racing was a thing. I stand corrected.
Before you read any of the things I write, I want to say that I enjoyed the experience. It had an appropriate mix of adrenaline and skill. I walked away bruised and bloodied, but still had lots of fun (just kidding on the bloodied part).
Basically, the premise is you drive around the track in a kart. You try to drive as fast as possible. They have electronic devices that measure how fast you go. Then, they rank you based on how fast your fastest lap was.
After the race, they upload your scores to a portal on the Internet. You get unfortunately named “ProSkill” points, and they maintain a leaderboard to see who is the best person.
We went around the track three times. I beat my brother, Jason, twice, and he beat me once. The time he beat me, though, he only beat me by 0.320 seconds, out of a 31-second lap. That’s approximately 1%.
So we got to thinking - there’s no possible way that the karts themselves are accurate to within 1% tolerances. These things go through incredible amounts of wear, ranging from the electrical system (the battery withstands approximately 5 rapid charge cycles every day, and puts out 15kW) to the smooth rubber tires, which grip the concrete like superglue and shreds rubber like a pencil eraser.
They post the scores for every race on the Internet. So, off to Scrapy to download them all.
Their website is composed of two different types of pages, “customer” pages and “heat” (race) pages. Each customer gets an ID, as well as a page on each location’s domain name (each of their ~36 locations has a different domain name). Each heat gets an ID that is unique to that location. For example, heat 154614 at Austin is a different heat than 154614 at Dallas. However, player 10262567 at Austin is the same player as player 10262567 at Dallas. To download all of the pages, we want to use player pages to download heat pages, and use heat pages to download player pages (they link to each other in that way, but there is no way to iterate through all players, for example). I’ll leave out the details of parsing the data as an exercise to the reader.
Since, as web scrapes generally go, this process would be interrupted constantly, I decided to use the builtin HTTP cache. This was a mistake. It does not scale well, at least not on my filesystem. The way the builtin cache works is it hashes the request, and then saves six files under a folder with that hash as a name. The six files are the request and response bodies, headers, and other metadata. Retrieving any cached request requires opening and reading multiple files, as well as retrieving the filesystem metadata to get last modify time (if you care about cache expiration). Checking for a response, likewise, requires checking to see if the right folder exists.
The problem with this approach, is after ~6 million pages (K1 Speed boasts that millions of players have played there - a very conservative guess of 1 million players + 100,000 heats per location gives us about 40 million pages across all sites). For one, ext4 filesystems allocate 4KB per file even for very small files, such as request heaters and metadata, so a single cached response is guaranteed to be at least 24KB (4KB * 6 files). On top of this, each file uses an inode, so after 6 million pages my filesystem ran out of inodes long before it ran out of space.
So between the performance hit (of constantly touching the filesystem) and the running out of space, I realized I would have to do better. Instead of creating 6 files for each request, one thing we can do is pack all requests into a single giant file. As a reasonable format, one can (for each record) spit the hash, then each of the 6 record components each preceded by an integer denoting the length of the data.
This makes it easy to cache data (just append to the end), but what about retrieving from the cache? When we want to retrieve a cached request, we don’t know where in the file it’s stored. So, we can trivially keep a giant dictionary mapping the hash to the offset in the file. For good measure, we can memory map the file, to make accessing it fast.
Note that I’m memory mapping a file that I’m appending to. Generally the memory map won’t have access to the newly appended parts of the file, but this is fine - I don’t worry about cache expiration, and the de-duplication filter in Scrapy will kick out everything not in the mmap, so I don’t have to access it.
Crisis averted.
Ordinarily, I have a “I tried this, but then it sucked, so I tried this”, but this actually worked pretty well, with minor iterative improvements. Indexing by brute force at the start of scraping takes ~10 minutes for a 50GB dataset, and the dictionary is only GB in size, at most.
Most of the memory usage was in fact storing the request queue, but that can be stored on disk.
That issue solved, the other issue was that Scrapy’s queue is domain-agnostic. I’m pulling from 36 domains - if one of them is slow, the others can still run. However, if the request priorities aren’t right, then the queue can fill up such that the workers are only pulling requests for a single domain, and if the max per-domain concurrency is hit they won’t try to go find a request for a different domain. They’ll just wait.
I spent some time tweaking the priorities. I found out that if you store your request queue on disk and don’t have bounded priorities, then you will get a “too many open files” error eventually.
But, I did eventually get the data. 54GB of raw gzip-compressed HTTP, 6GB (13 million records) of parsed JSON data. 205 thousand players who played a race in Austin. 97 thousand races over approximately ten years, comprising 655 thousand kart-races (two karts in one race is two kart-races, as is one kart in two races).
Peanuts compared to some professions I can name (most, really). But hopefully enough to answer the question.
To the heart of the matter. I wrote a script that computes the average “best lap” time of each kart over all of 2017 (add up the times, divide by the number of races the kart did in 2017). Karts generally did about 2000 races from 1/1/2017 to 10/31/2017, or an average of almost 7 a day. The way karts are assigned appears to be random, so it shouldn’t be that skilled players tend to end up on certain karts, skewing the averages.
There are 50 karts, but karts 41-50 are the kid karts, which are about 30% slower. So I discounted those in all further analysis.
As it turns out, there is in fact a skew of over a second between the fastest kart and the slowest, with a fairly even distribution between 32 and 33 seconds (and a few outliers also). I even made a graph (my favorite thing in the world):
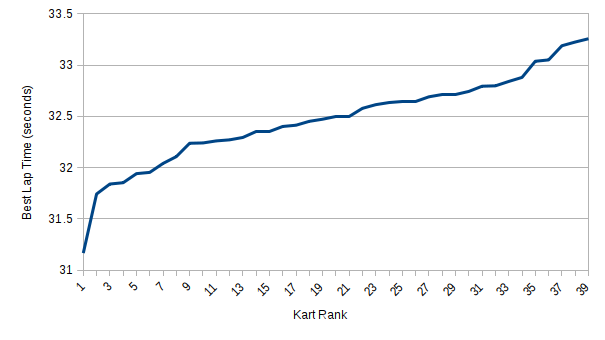
The real question is, of course, does this affect anyone’s rankings?
The answer is, yes, yes it does. I just analyzed the three games my family played, by normalizing each racer’s best lap time against the average time for the kart (so if your kart has a slow average, you’ll increase in ranking, but if it has a fast average, you’ll decrease). In one of the three games my family played, I went from beating my brother by 0.429s to losing by 0.278s. In two of the three games, my sister went from second-to-last place to last place. In two of the games, the person in second place gained almost a half second on the person in first place, in each case going from about 0.9 seconds behind to about 0.3 seconds behind.
So that is the grand lie. Your times are measured to the millisecond, and scores are assigned based on those hard numbers, but the karts themselves are only accurate to the second.
